一、前言
最近工作找的很是捉急,各种碰壁Zz~(~ o ~)~zZ。哎,说到头还是自己知识储备少,不深入。去一家公司面试前端,被问得是哑口无言,“说说浏览器是怎么渲染的?”、“如果要你用原生JS去解析JSON你会怎么做?”、“有自己的JS库吗?”。。。我TM怎么知道浏览器是如何渲染的,TM这是多高端的东西。劳资也只是刚出道一年,也就会写写页面、改改样式。TM我怎么知道如何去写原生的JSON解析,javascript不是有封装好的JSON解析API,鬼才会去想怎么实现啊,就面试那几分钟你能给个方案?。TM我就不信我不会这些会影响工作。。
很牢骚是吗?一点也不。程序猿不经常牢骚那该会多么无趣啊!不过呢牢骚完了咱还得回头整整不是。没办法,谁叫咱菜啥也不会呢,要我是大牛我一定给你整趴下(TM当场就拒绝我,不会委婉点啊!没品,迟早出门掉钱..)。不过话说回来,我也很想知道像我们这群码农必定整天都要打交道的浏览器到底是咋工作?有什么深奥的Knowledge?
二、How browsers work
外国人的东西当然他们更懂,特别欣赏他们那种Open、Share和Free的理念,不像国人XX@#@#@#$$。How browsers work —-这个文章介绍了浏览器从头到尾的工作机制,如:HTML的解析、DOM树的生成、CSS的渲染等。为了拓展一下视野,不再被人鄙视,GO!!!
2.1 浏览器是做啥的?
当今地球主流浏览器有五类:IE(Internet Explorer)、Firefox、Safari、Chrome和Opera.那么它们是用来做什么呢?还用讲,当然是用来上网的呗,谁的速度快我就用谁~
浏览器的主要功能是展示网页资源,即用户请求url后将结果显示在浏览器窗口。可以展示包括Html、PDF、picture和文字等。
2.2 浏览器的上层结构
浏览器的主要歹念如下:
- 用户接口:包括地址栏、前进、后退、书签菜单等窗口上出了网页显示区域以外的部分。
- 浏览器引擎: 查询与操作渲染引擎的接口
- 渲染引擎: 负责显示请求的内容。比如请求到
HTML,它会负责解析HTML与CSS并将结果显示到窗口中。 - 网络:用于网路请求。如
http请求。 UI后端: 回执基础元件。如组合框与窗口。Javascript解析器: 用于解析执行Javascript代码。- 数据存储:这是一个持久层。浏览器需要把所有数据存到硬盘上。如:cookies.
HTML5规定了一个完整的浏览器中的数据库:“web database”。
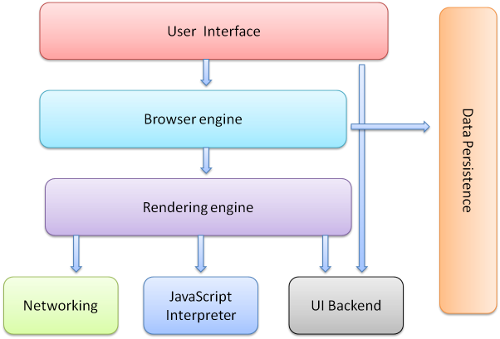
图1 浏览器的主要概念
note: 与其他浏览器不同,chrome使用多个渲染引擎实例,每个TAB都是一个独立的进程。
2.3 渲染引擎
关于渲染引擎,FireFox使用Gecko; Mozilla用自家的渲染引擎;Safari和chrome都使用Webkit.
Webkit是一个开源的渲染引擎,它源自Linux平台,经过Apple公司的修改可以支持Mac与Window平台。http://webkit.org
2.4 The main flow
渲染引擎开始于从网络层获取请求内容,一般是不超过8K的数据块。接下来就是渲染引擎的基本工作流程:

图 2:渲染引擎的基本工作流程
基本工作流分别是:解析Html、构建DOM树、渲染树结构、渲染树布局、绘制渲染树。渲染引擎会解析HTML文档并把标签转换成内容树中的DOM节点。它会解析style元素和外部文件中的样式数据,样式数据和Html中的现实控制将共同用来创建另一棵树—渲染树。
渲染树包含带有颜色、尺寸等显示属性的矩形。这些矩形的顺序与显示顺序一致。渲染树构建完成后就是“布局”处理,也就是确定每个节点在屏幕上的确切显示位置。下一步骤是“绘制”——遍历渲染树并用UI后端层将每一个节点绘制出来。为了更好的用户体验,渲染引擎会尝试尽快的把内容显示出来。它不会等到所有HTML都被解析完才创建并布局渲染树。它会 在处理后续内容的同时把处理过的局部内容先展示出来。
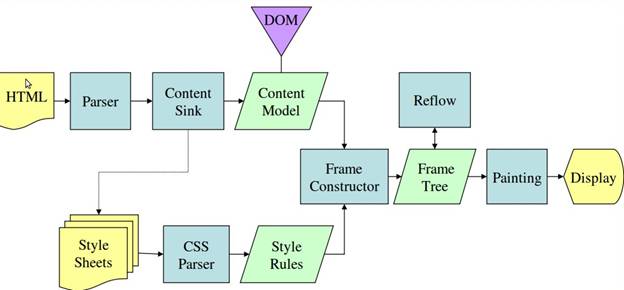
图3: Webkit主要流程
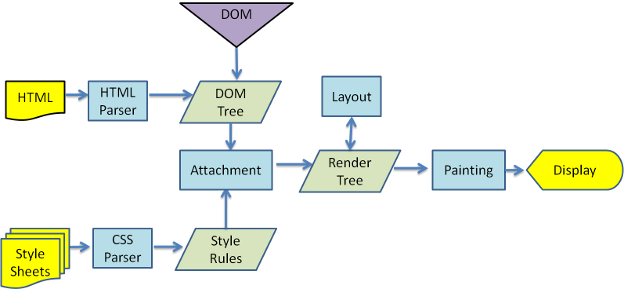
图4: Mozilla的Gecko渲染引擎主要流程
从上图可以看出,尽管Webkit与Gecko使用略微不同的术语,这个过程还是基本相同的。Gecko 里把格式化好的可视元素称做“帧树”(Frame tree)。每个元素就是一个帧(frame)。 Webkit 则使用”渲染树”这个术语,渲染树由”渲染对象”组成。Webkit 里使用”layout”表示元素的布局,Gecko则称为”Reflow”。Webkit使用”Attachment”来连接DOM节点与可视化信息以构建渲染树。一个非语义上的小差别是Gecko在Html与Dom树之间有一个附加的层 ,称作”content sink”,是创建Dom对象的工厂。
2.5 Parsing (解析)
解析一个文档意味着把它翻译成有意义的结构以供代码使用。解析的结果通常是一个由文档组成的树,称之为解析树或者语法树。示例——解析表达式“2 + 3 – 1” 可以返回下面树:
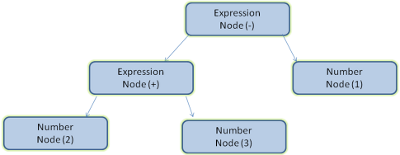
图5:表达式树节点
2.6 Grammars(语法)
解析是基于文档所遵循的语法规则——书写所用的语言或格式来进行的。每一种可以解析的格式必须由确定的语法与词汇组成。这被称之为上下文无关语法。人类语言并非此种语言,所以不能用常规的解析技术来解析。
2.7 Parser – Lexer combination (解析器—词法分析组合)
解析器有两个处理过程:词法分析与句法分析。词法分析负责把输入切分成符号序列,符号是语言的词汇——由该语言所有合法的单词组成。句法分析是对该语言句法法则的应用。解析器通常把工作分给两个组件——分词程序负责把输入切分成合法符号序列,解析程序负责按照句法规则分析文档结构和构建句法树。词法分析器知道如何过滤像空格,换行之类的无关字符。
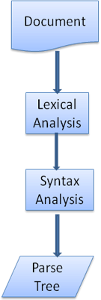
图6: 从源文档到解析树(文档、词法分析、语法分析、解析树)
解析过程是交互式的。解析器通常会从词法分析器获取新符号并尝试匹配句法规则。如果匹配成功,就在句法树上创建相应的节点,并继续从词法分析器获取下一个符号。如果没有匹配的规则,解析器会内部保存这个符号,并继续从词法分析器获取符号,直到内部保存的所有符号能够成功匹配一个规则。如果最终无法匹配,解析器会抛出异常。这意味着文档无效,含有句法错误。
2.8 Translation(转换)
多数情况下解析树并非最终结果。解析经常是为了从输入文档转换成另外一种格式。比如编译器要把源码编译成机器码,会首先解析成解析树,再把解析树转换成机器码。
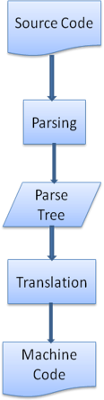
图7:编译过程(源码、解析、解析树、转换、机器码)
2.9 HTML DTD
HTML的定义使用DTD文件。这种格式用来定义SGML(Standard Generalized Markup language)标准通用标记语言族语言,它包含对所有允许的元素的定义,包括它们的属性和层级关系。如我们前面所说,HTML DTD构不成上下文无关语法。
DTD有几种不同类型。严格模式完全尊守规范,但其它模式为了向前兼容可能包含对早期浏览器所用标签的支持。当前的严格模式DTD:http://www.w3.org/TR/html4/strict.dtd
2.10 DOM
解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。DOM与标签几乎有着一一对应的关系,如下面的标签
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
会被转换成如的DOM树:
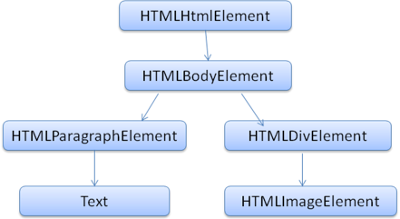
图8: DOM tree of the example markup
与HTML一样,DOM规范也由w3c组织制订。参考:http://www.w3.org/DOM/DOMTR. 这是一个操作文档的通用规范。有一个专门的模块定义HTML特有元素: http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
当我们说树中包含DOM节点时,意思就是这个树是由实现了DOM接口的元素组成。这些实现包含了其它一些浏览器内部所需的属性。
2.11 The parsing algorithm(解析算法)
如我们前面看到的,HTML无法使用自上而下或自下而上的解析器来解析。
原因如下:
- 语言的宽容特点
- 浏览器需要对无效
HTML提供容错的事实 - 解析过程的反复。通常解析过程中源码不会变化。但在
HTML中,script标签包含document.write时可以添加内容,即解析过程实际上还会改变源码。
浏览器创建了自己的解析器来解析HTML文档。HTML5规范里对解析算法有具体的说明,解析由两部分组成:分词与构建树。分词属于词法分析部分,它把输入解析成符号序列。在HTML中符号就是开始标签,结束标签,属性名称和属生值。分词器识别这些符号并将其送入树构建者,然后继续分析处理下一个符号,直到输入结束。
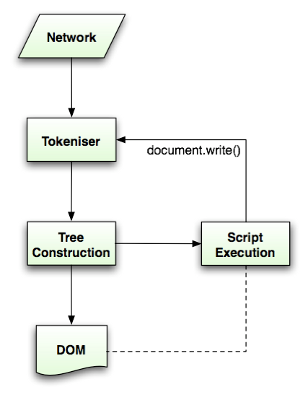
图9: HTML解析流程 (源自HTML5规范)
暂时只了解这么多了,有空再学习学习~ 这里还有两篇 <<浏览器的渲染原理简介>>、<<浏览器加载和渲染HTML的顺序以及Gzip的问题>> 文章,得抽空观摩观摩!!!
参考资料:
